Email Topic Extraction and Clustering with Non-negative Matrix Factorization
So I was checking some email and found myself inundated with not-quite-spam. I bet that you have a lot of email that is neither totally unwanted scam emails, nor personal correspondence. You probably want to pay different levels of attention to the these mails based on their content. Wouldn’t it be great if you could automate all of your email handling?
Let’s take a look at a corpus of emails and extract topic structure with Non-negative Matrix Factorization. You can use run this code on your computer to use the email currently stored on your desktop and find patterns in your email. This post uses the mails currently stored in my Maildir. It turns out that most of my email is sent by machines!
The first step is to include dependencies and define some helper functions
%matplotlib inline
import pip
pip.main(['install', 'scipy', 'sklearn', 'matplotlib', 'pandas'])
from __future__ import print_function
from time import time
import mailbox
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.decomposition import NMF, LatentDirichletAllocation
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
plt.rc('font', **{'family' : 'monospace',
'weight' : 'bold',
'size' : 30})
n_samples = 40000
n_features = 2000
n_topics = 10
n_top_words = 30
Accessing the Email
The Python standard library mailbox module provides easy access to emails in the Maildir format. You can use the great tool isync/mbsync to synchronize your email to your desktop. I have used it on Linux and OSX.
A small aside on the benefits of open technology and owning your own systems: The following code allows us to process all the email on my desktop. There is no API to enroll in, no keys to manage, and no corporations that can control my data. This freedom is enabled by owning your data. Fortunately, all mainstream email providers support the IMAP protocol and so you can own your own email.
md = mailbox.Maildir("/home/james/Maildir/jjpfnet/INBOX")
# The code in this cell (and only this cell) is modified from @Tyndyll's
# gist https://gist.github.com/tyndyll/6f6145f8b1e82d8b0ad8
# which is available on gist.github.com
def extract(msg, msg_obj, attachments):
if msg.is_multipart():
for part in msg.get_payload():
if part.is_multipart():
extract(part, msg_obj, attachments)
continue
if part.get('Content-Disposition') is None:
msg_obj["body"] += part.get_payload()
else:
if part.get('Content-Disposition').startswith('attachment'):
attachments[part.get_filename()] = {
'data': part.get_payload(decode=True),
'mime': part.get_content_type()
}
else:
msg_obj["body"] += msg.get_payload()
return
"""
messages(mdir) is a generator for message objects from a maildir object.
"""
def messages(mdir, directory):
for msg in mdir:
msg_obj = {"path": directory, "body": ""}
attachments = {}
for key, value in msg.items():
msg_obj[key.lower()] = value
lists = ["from", "cc", "bcc", "to"]
extract(msg, msg_obj, attachments)
yield msg_obj, attachments
All you have to do is open the mailbox and pull out all the subject and body text. In order for an Machine Learning tool to work you have to filter out some noise. Email has a lot of junk that shows up in some machine generated emails. The most important thing is to remove as much of the random strings that aren’t words from the corpus. Minified HTML,JS, and CSS also make processing more difficult.
This filtering step would be much more involved in a production application of data analysis. You would have to do the heavy lifting of extracting as much useful text as possible while discarding the noise.
i = 0
bodies = []
allsubs = []
body = ''
mesgs = messages(md, "INBOX")
for mesg, attach in mesgs:
try:
# we need to filter out long words because they are either
# minified javascript/css or API keys
body = ' '.join(filter(lambda x: len(x) <25, mesg['body'].split()))
except Exception as ex:
print('No body found for message {}'.format(mesg))
print('\tException: {}'.format(ex))
bodies.append(body)
allsubs.append(mesg['subject'])
i+=1
if i > n_samples:
break
# then we throw out documents with less than 2 words
# this catches a lot of emails that were completely composed of
# minified css and js
data_samples = list(filter(lambda x: (len(x.split()) > 2), bodies))
subs = []
for i, bdy in enumerate(bodies):
if len(bdy.split()) > 2:
subs.append(allsubs[i])
print('The number of documents is: {}'.format(len(data_samples)))
The number of documents is: 4263
4,000 emails is not that much, but we can still apply these techniques. A good comparison would be a deep neural net, which might take 1-2 orders of magnitude more data to train.
Take a look at some of my email for fun. You should be able to eyeball the difference between mail that came from an automated system (potential spam) from email that came from humans.
This is the account that receives my github notifications so a lot of the email is about code.
for i, x in enumerate(data_samples[0:10]):
print('Subject: {}'.format(subs[i]))
print('Body:')
print(x[:min(240, len(x))])
print('------------------------------Message Truncated-----------------\n')
Subject: Re: Pollux has an inconsistent root file system.
Body:
I am also forwarding this email to Anita who has root privileges on the cas= tor and pollux. Best, Oded From: Jason Riedy Sent: Monday, April 10, 2017 2:52 PM To: Ediger, David M; Robert McColl; James Fairbanks; Green, Oded Subject: Pollux
------------------------------Message Truncated-----------------
Subject: Purchase order -241PO1800282
Body:
Dear Sir, Please find attached purchase order for your reference. Kindly qoute your best prices with proforma invoice, payment terms and delivery schedule. Thanks & Best Regards Mr. Jafar Sadiq Sales Excutive Mob: S
------------------------------Message Truncated-----------------
Subject: Re: How is the atomic arrays going
Body:
Hi James, I wrote a package implementing the functionality called UnsafeAtomics.jl<ht= I just ported all the relev= ant atomic tests from Base.Threads tests to the unsafe package and they all= pass. I think I will post on the list as a foll
------------------------------Message Truncated-----------------
Subject: Re: [JuliaGraphs/LightGraphs.jl] should is_cyclic return true on a
2-node PathGraph? (#592)
Body:
Closed #592. -- You are receiving this because you were mentioned. Reply to this email directly or view it on GitHub: <a class="issue-link js-issue-link" data-id="221955592" data-error-text="Failed to load issue title" title is private">#59
------------------------------Message Truncated-----------------
Subject: RE : Potential Position for Senior DevOps Engineer/System Administrator Loc: Princeton, NJ Dur: 6+ M Rate: OPEN
Body:
<p>Hi, </p> <p> I received your contact from a referral as a potential for contract / full time position. Based on what I learnt, I feel you might be suitable for the following position as given in the job description attached at the bottom
------------------------------Message Truncated-----------------
Subject: Re: [jpoovey3/HDAPWorkflows] Move execution to self.run method; Add
docstrings; (#1)
Body:
@jfairbanks6, did you want to go ahead and merge this one? I've been working on another branch `plp_model` for finishing up the modeling workflow. -- You are receiving this because you were mentioned. Reply to this email directly or view it
------------------------------Message Truncated-----------------
Subject: Re: [JuliaGraphs/LightGraphs.jl] WIP: LightGraphs Abstraction (#541)
Body:
@sbromberger pushed 1 commit. d8d12ce 1.0 -> 0.8 -- You are receiving this because you are subscribed to this thread. View it on GitHub: <p><a pushed 1 commit.</p> <ul> <li><a 1.0 -> 0.8</li> </ul> <p />You are receiving this because you
------------------------------Message Truncated-----------------
Subject: Re: [stingergraph/stinger] compile without warnings (#218)
Body:
@zeuner pushed 1 commit. 3eaf610 linking related fixes -- You are receiving this because you are subscribed to this thread. View it on GitHub: <p><a pushed 1 commit.</p> <ul> <li><a linking related fixes</li> </ul> <p />You are receiving th
------------------------------Message Truncated-----------------
Subject: Re: [JuliaGraphs/LightGraphs.jl] WIP: Eager implementation of Prim's
algorithm (#530)
Body:
Oh! I hope you're feeling better. -- You are receiving this because you were mentioned. Reply to this email directly or view it on GitHub: I hope you're feeling better.</p> <p />You are receiving this because you were mentioned.<br />Reply
------------------------------Message Truncated-----------------
Subject: Re: [JuliaGraphs/LightGraphs.jl] merge vertices operator (#676)
Body:
# Report > Merging into will **decrease** coverage by `0.39%`. > The diff coverage is `0%`. ```diff @@ Coverage Diff @@ ## master #676 +/- ## - Coverage 100% 99.6% -0.4% Files 59 59 Lines 3026 3038 +12 Hits 3026 3026 - Misses 0 12 +12 ``` -
------------------------------Message Truncated-----------------
Running the Model
After all that work to get the data ready, it is time to fit a model to the data! Good thing our friends at Sklearn have made NMF and TF-IDF feature extraction a simple library call. TF-IDF is the matrix that is derived from a corpus of text where each entry of a matrix $A$ is defined as the $A[i,j]$ is the frequency of the $j$th term in the $i$th document divided by the number of documents that contains term $j$. This matrix captures the idea that common words are less semantically important than rare words.
This code adapted from the Sklearn documentation.
# Use tf-idf features for NMF.
print("Extracting tf-idf features for NMF...")
tfidf_vectorizer = TfidfVectorizer(max_df=0.95, min_df=2,
max_features=n_features,
stop_words='english')
t0 = time()
tfidf = tfidf_vectorizer.fit_transform(data_samples)
print("done in %0.3fs." % (time() - t0))
# Fit the NMF model
print("Fitting the NMF model with tf-idf features, "
"n_samples=%d and n_features=%d..."
% (n_samples, n_features))
t0 = time()
nmf = NMF(n_components=n_topics, random_state=1,
alpha=.1, l1_ratio=.5).fit(tfidf)
print('NMF took {} iterations of CD'.format(nmf.n_iter_))
print("done in %0.3fs." % (time() - t0))
tfidf_feature_names = tfidf_vectorizer.get_feature_names()
Extracting tf-idf features for NMF...
done in 2.683s.
Fitting the NMF model with tf-idf features, n_samples=40000 and n_features=2000...
NMF took 134 iterations of CD
done in 0.931s.
Now we want to visualize the topics. The first step is to view them as lists of words. The machine has only learned sets of words it doesn’t have any idea of conceptual similarity of the words. They are just words that make good low rank factors to the TF-IDF matrix. Fortunately your brian will identify “topics” when you read the lists of words. Or, at least it would if this were your email!
def top_words(topic, n_top_words):
return topic.argsort()[:-n_top_words - 1:-1]
def topic_table(model, feature_names, n_top_words):
topics = {}
for topic_idx, topic in enumerate(model.components_):
t = ("topic_%d:" % topic_idx)
topics[t] = [feature_names[i] for i in top_words(topic, n_top_words)]
return pd.DataFrame(topics)
topic_table(nmf, tfidf_feature_names, n_top_words).head(10)
| topic_0: | topic_1: | topic_2: | topic_3: | topic_4: | topic_5: | topic_6: | topic_7: | topic_8: | topic_9: | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | issue | 3d | pushed | 09 | span | li | td | itemprop | coverage | hotline |
| 1 | itemprop | class | commit | 3d | font | h4 | tr | pull | diff | lc |
| 2 | title | br | itemprop | 100 | 0in | strong | border | meta | 3d | token |
| 3 | data | div | pull | table | style | ul | style | github | span | otp |
| 4 | meta | href | ul | mso | msonormal | patch | table | div | pl | ocf |
| 5 | github | 20 | thread | 2c | size | merge | font | view | report | access |
| 6 | link | e2 | li | 0pt | mso | changes | align | request | 100 | llnl |
| 7 | div | open | meta | rspace | 3d | summary | width | directly | lines | livermore |
| 8 | view | code | subscribed | adjust | color | comment | important | reply | merging | 925 |
| 9 | js | dir | github | tbody | margin | links | padding | itemscope | hits | 422 |
Analyzing the Results
The results of the matrix factorization can give us the list of words in each topic, but we want to know more about the structure of the data. Is there structure between the topics? How do the documents break down in terms of topics? Are there clusters of documents? Can we detect spam with this model?
gittopics = [0,2,5,7,8]
csstopics = [1,3,4,6]
docweights = nmf.transform(tfidf_vectorizer.transform(data_samples))
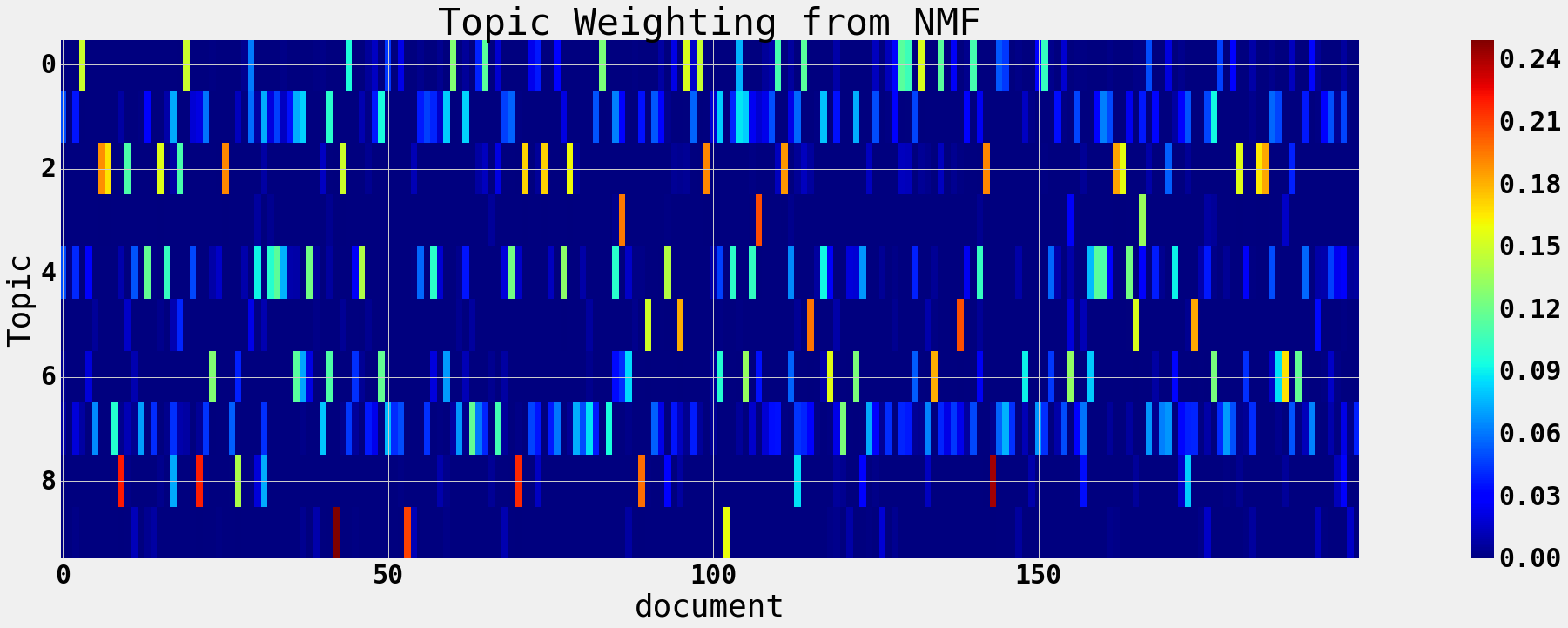
plt.figure(figsize=(40,10))
plt.imshow(docweights[0:200, :].T, aspect=8, interpolation='none')
plt.title('Topic Weighting from NMF')
plt.xlabel('document')
plt.ylabel('Topic')
plt.colorbar()
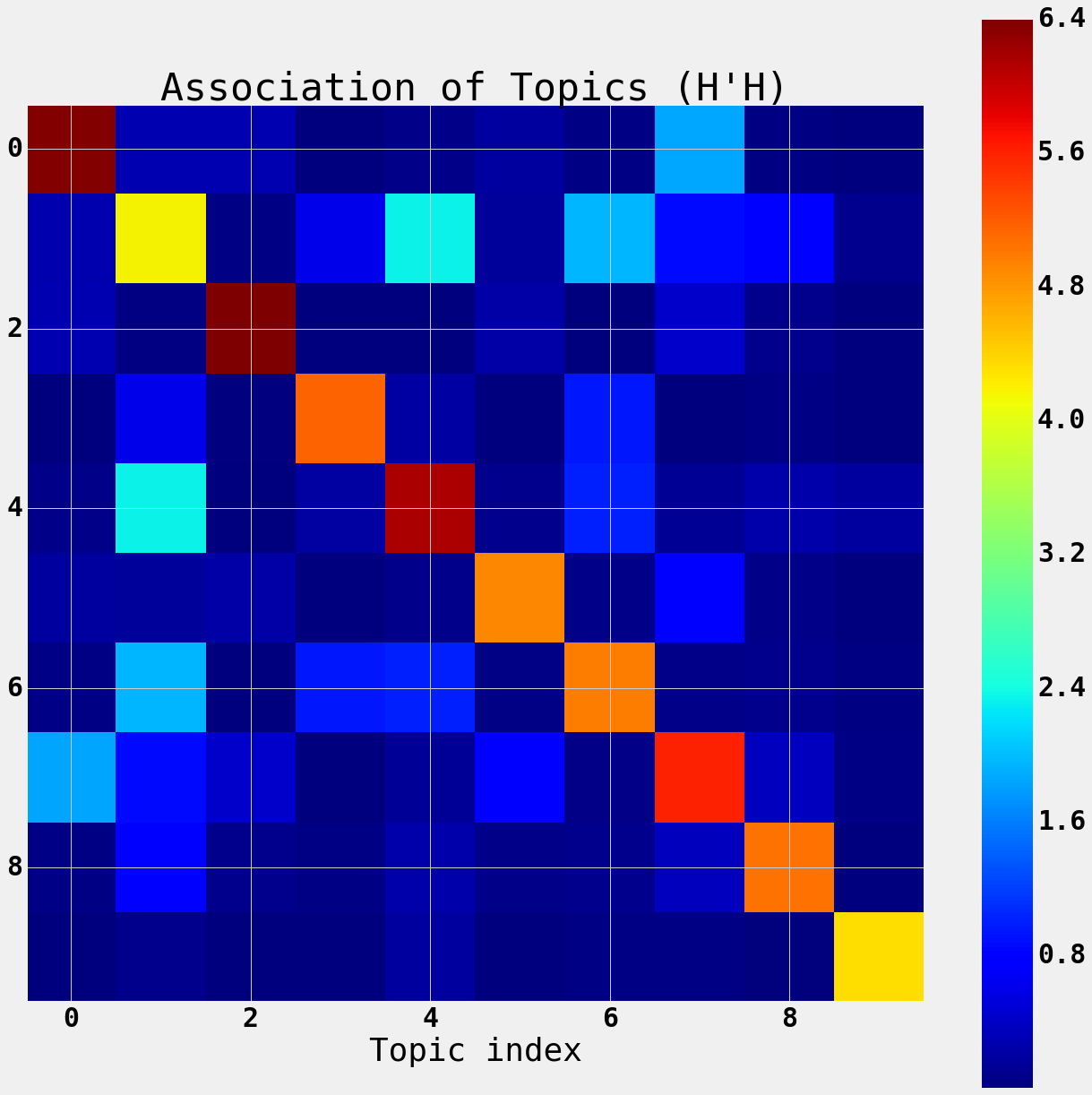
We can also see the association between the topics by computing the inner product of the normal equations for the topic-document matrix.
$$ A \approx HW $$
$A$ is documents by words $H$ is documents by topics and $W$ is topics by words.
The product $H’H$ is the association of the topics with each other based on occuring in the same documents.
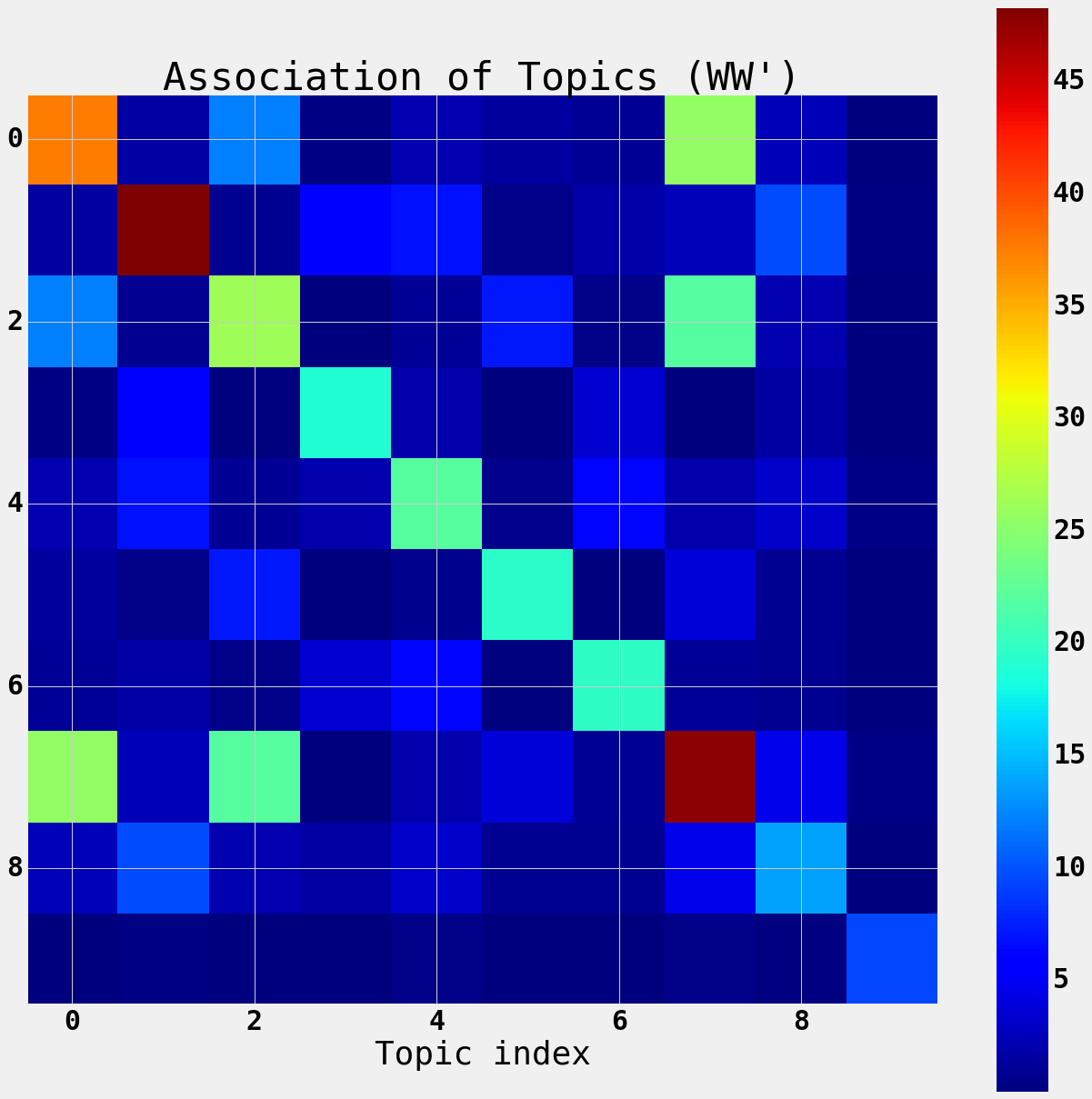
The product $WW’$ is the association of the topics with each other based on their overlapping distributions of words.
A = tfidf_vectorizer.transform(data_samples)
W = nmf.components_
H = nmf.transform(A)
print('A is {} x {}'.format(*A.shape))
print('W is {} x {}'.format(*W.shape))
print('H is {} x {}'.format(*H.shape))
A is 4263 x 2000
W is 10 x 2000
H is 4263 x 10
Here we see that there are sets of topics that share a lot of documents. These topics are related to each other.
Topics gittopics share a lot of documents.
Topics csstopics share a lot of documents, they are topics related to code.
These associations will come up in more detail later.
print('Git Topics: ', gittopics)
print('CSS Topics: ', csstopics)
Git Topics: [0, 2, 5, 7, 8]
CSS Topics: [1, 3, 4, 6]
plt.figure(figsize=(20,20))
plt.imshow(H.T.dot(H), interpolation='none')
plt.colorbar()
plt.title("Association of Topics (H'H)")
plt.xlabel('Topic index')
Here you can see that the words offer some structure to the topics.
Topics 5 and 6 overlap which matches the intuition that they are both sets of CSS related words.
However topics 0,2,4, and 7 have some overlap as they are topics related to code. Topic 9 is about LLNL
plt.figure(figsize=(20,20))
plt.imshow(W.dot(W.T), interpolation='none')
plt.colorbar()
plt.title("Association of Topics (WW')")
plt.xlabel('Topic index')
Spot Checking the Data: Annecdatal evidence
One of the reasons that Machine Learning is so popular with Images, Text, and Audio is that humans are equiped for making judgements about accuracy in these media. By comparison, mechanical failures, geospatial data, medical records are all complicated domains where humans don’t have a natural ability to judge correctness. The other reason, of course, is the ubiquity of Images, Text, and Audio on the web.
So let’s use our human abilities to recognize accuracy on this clustering problem and spot check the clusters.
Topic models yield a clustering technique by associating each document with its dominant topic and then looking at representative examples from each cluster.
df = pd.DataFrame({'subject':subs,
'topic':docweights.argmax(axis=1),
'body':data_samples},
columns=['topic', 'subject', 'body'])
"""
showdocs(df, topics, nshow=5) is a function that gathers a number of
documents from a set of topics as a dataframe.
"""
def showdocs(df, topics, nshow=5):
idx = df.topic == topics[0]
for i in range(1, len(topics)):
idx = idx | (df.topic == topics[i])
return df[idx].groupby('topic').head(nshow).sort_values('topic')
These topics are mostly from Newsletters and are identified by their CSS words like font, 0pt, width, padding, margin, quot, align, serif.
showdocs(df, csstopics)
| topic | subject | body | |
|---|---|---|---|
| 0 | 1 | Re: Pollux has an inconsistent root file system. | I am also forwarding this email to Anita who h... |
| 48 | 1 | Re: [JuliaGraphs/LightGraphs.jl] Implementing ... | > Also adding code will make it go from workin... |
| 37 | 1 | Voided: Contract Documents for James Fairbanks... | Hello James Fairbanks, Contract Documents for ... |
| 22 | 1 | Re: [JuliaGraphs/LightGraphs.jl] WIP: simplegr... | There appears to be a slight regression in ```... |
| 35 | 1 | Subject: Daily report mailbox james@jp... | Your folder Spam contains 11 new messages. Sum... |
| 107 | 3 | =?utf-8?Q?Our=202016=20annual=20report?= | From GIFs in email campaigns to physical tons ... |
| 86 | 3 | =?utf-8?Q?Electronic=20resources=20=2D=2D=20ge... | News from the Georgia Tech Library. View this ... |
| 66 | 3 | [cse-mirasol-users] /home cleanup time | Recent power outages made me aware that /home ... |
| 166 | 3 | =?utf-8?Q?Python=20Weekly=20=2D=20Issue=20302?= | Email not displaying correctly? View it in you... |
| 219 | 3 | Reminder: Register for 1/25 ACM-SIGAI Panel on... | Reminder: Register for 1/25 ACM-SIGAI Panel on... |
| 13 | 4 | Computation All Hands - Monday, October 31, B1... | All Computation employees and visitors are inv... |
| 11 | 4 | SIAM Content Provider Upgrade | Dear James Fairbanks, As a valued member of SI... |
| 4 | 4 | RE : Potential Position for Senior DevOps Engi... | <p>Hi, </p> <p> I received your contact from a... |
| 2 | 4 | Re: How is the atomic arrays going | Hi James, I wrote a package implementing the f... |
| 1 | 4 | Purchase order -241PO1800282 | Dear Sir, Please find attached purchase order ... |
| 41 | 6 | James, is this you? | James, we think this publication is yours. Con... |
| 45 | 6 | Investment prospectus | A new prospectus is available for each of your... |
| 49 | 6 | Happy Holidays from Wealthfront | View in browser ]> Happy Holidays from Wealthf... |
| 23 | 6 | New Meetup Group: TEDxPeachtree "365" | TEDxPeachtree "365" Do you believe ideas can s... |
| 36 | 6 | =?utf-8?q?Natalie_and_2_others_made_changes_in... | Here=E2=80=99s what happened in your shared fo... |
These topics are mostly from Github and relate to code, with words like pull, commit, julia, graph, mergining, application.
showdocs(df, gittopics, nshow=3)
| topic | subject | body | |
|---|---|---|---|
| 3 | 0 | Re: [JuliaGraphs/LightGraphs.jl] should is_cyc... | Closed #592. -- You are receiving this because... |
| 19 | 0 | Re: [JuliaGraphs/LightGraphs.jl] Just a note r... | Closed #584. -- You are receiving this because... |
| 29 | 0 | Re: [JuliaGraphs/LightGraphs.jl] `connected_co... | OK, so after talking with @jpfairbanks I've do... |
| 6 | 2 | Re: [JuliaGraphs/LightGraphs.jl] WIP: LightGra... | @sbromberger pushed 1 commit. d8d12ce 1.0 -> 0... |
| 7 | 2 | Re: [stingergraph/stinger] compile without war... | @zeuner pushed 1 commit. 3eaf610 linking relat... |
| 10 | 2 | Re: [JuliaGraphs/LightGraphs.jl] first cut at ... | @sbromberger pushed 2 commits. d95252b Merge b... |
| 88 | 5 | eCopyright | Dear James, This is to inform you that the eco... |
| 90 | 5 | [stingergraph/stinger] Release candidate for 1... | You can view, comment on, or merge this pull r... |
| 95 | 5 | [nassarhuda/MatrixNetworks.jl] biconnected com... | You can view, comment on, or merge this pull r... |
| 5 | 7 | Re: [jpoovey3/HDAPWorkflows] Move execution to... | @jfairbanks6, did you want to go ahead and mer... |
| 8 | 7 | Re: [JuliaGraphs/LightGraphs.jl] WIP: Eager im... | Oh! I hope you're feeling better. -- You are r... |
| 12 | 7 | Re: [JuliaGraphs/LightGraphs.jl] Add various a... | Yes, I will open a new PR for that one, so tha... |
| 9 | 8 | Re: [JuliaGraphs/LightGraphs.jl] merge vertice... | # Report > Merging into will **decrease** cove... |
| 17 | 8 | Re: [simonster/Memoize.jl] Support function re... | [![Coverage Coverage decreased (-2.7%) to 92.3... |
| 21 | 8 | Re: [JuliaGraphs/LightGraphs.jl] Update binomi... | # Report > Merging into will **not change** co... |
Analysis of Residuals
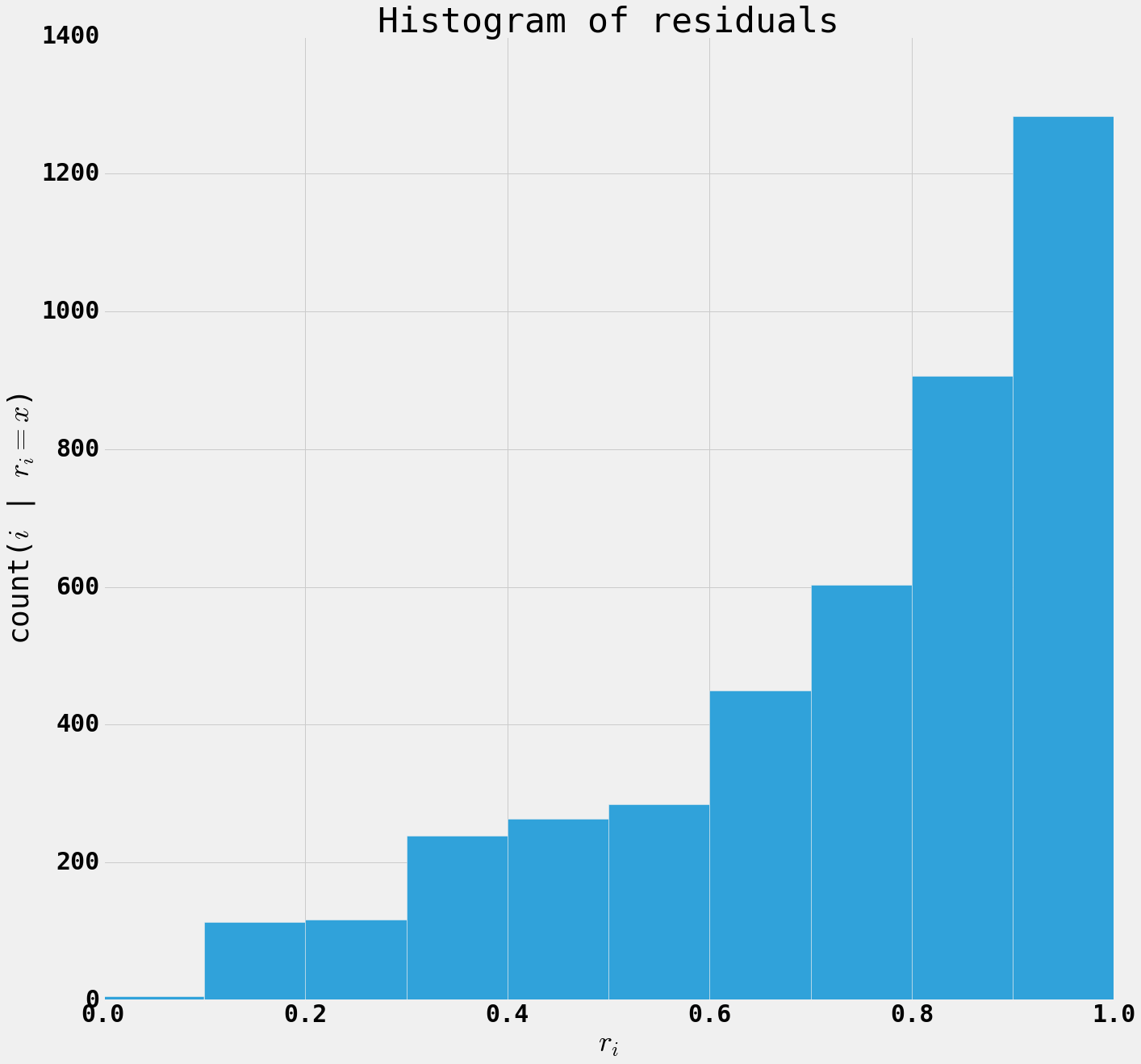
We can look at the quality of the model on various documents. For some documents the text is well approximated by the latent factors, but for some other documents the text is poorly approximated by the topics.
The residual for a document is defined as $$ r[i] = ||A[i,:] - H[i,:]W||_2 $$
When $r[i]$ is small the model is capturing the text of the document, when the residual is large, the document is using some combination of words that does not lie on the subspace spaned by the word vectors (columns of W).
We see that the residuals are small for documents that fit the mental category that we assign to the topic and large for documents that are individualized and personal.
import numpy as np
r = np.zeros(A.shape[0])
for row in range(A.shape[0]):
r[row] = np.linalg.norm(A[row, :]- H[row,:].dot(W))
print(sum(np.sqrt(r)))
nmf.reconstruction_err_
3615.85321153
50.592531594804974
plt.figure(figsize=(20,20))
plt.hist(r);
plt.title('Histogram of residuals')
plt.xlabel('$r_i$')
plt.ylabel('count($i$ | $r[i] = x$)')
df['residual'] = r
df.sort_values(['topic','residual'],
ascending=True).groupby('topic').head(5)
| topic | subject | body | residual | |
|---|---|---|---|---|
| 1391 | 0 | Your modified booking at ... | rkJggg== SUVORK5CYII= RdFfAAAAAElFTkSuQmCC | 0.000000 |
| 1467 | 0 | Your booking at ... | PC9ib2R5Pgo8L2h0bWw+ cn0m6T8AAAAASUVORK5CYII= ... | 0.000000 |
| 1505 | 0 | Your booking at ... | 2Q== rkJggg== SUVORK5CYII= RdFfAAAAAElFTkSuQmCC | 0.000000 |
| 4002 | 0 | James, ready to travel? | g5EAAAAASUVORK5CYII= AAAASUVORK5CYII= TkSuQmCC | 0.000000 |
| 4016 | 0 | You have a new message from Windsor Guest House. | Wl0tLS6Wlr//2Q== BnnV4dXRkf/Z YII= | 0.000000 |
| 3757 | 1 | Re: [JuliaGraphs/LightGraphs.jl] WIP: Eager im... | -- You are receiving this because you were men... | 0.417925 |
| 357 | 1 | Re: [flycheck/flycheck] Add proselint checker ... | Any progress? 🙄 -- You are receiving... | 0.450220 |
| 4228 | 1 | Georgia Tech Yellow Jackets Latest News | August 17, 2016 In This Issue ______________ 2... | 0.505818 |
| 695 | 1 | Georgia Tech Yellow Jackets Latest News | August 30, 2016 In This Issue ______________ G... | 0.531093 |
| 733 | 1 | Funding and Networking in Academemia - all you... | To view this message in HTML format, click her... | 0.531405 |
| 1741 | 2 | Re: [rohitvarkey/rohitvarkey.github.io] Part 4... | @rohitvarkey pushed 1 commit. 1c2df2d Incorpor... | 0.130336 |
| 1875 | 2 | Re: [JuliaGraphs/LightGraphs.jl] Transitivity ... | @AsileBcd pushed 1 commit. 02b9b7f Efficiency ... | 0.130336 |
| 2175 | 2 | Re: [rohitvarkey/StingerWrapper.jl] WIP: LG ab... | @rohitvarkey pushed 1 commit. 2158036 Iterator... | 0.130336 |
| 2317 | 2 | Re: [JuliaGraphs/LightGraphs.jl] Pull request/... | @AsileBcd pushed 1 commit. 2d20b8e Fixing inde... | 0.130336 |
| 2541 | 2 | =?UTF-8?Q?Re:_[stingergraph/stinger]_Trying_CM... | @davidediger pushed 1 commit. a778e8a Upgradin... | 0.130336 |
| 2520 | 3 | =?utf-8?Q?Big=20Announcement?= | View this email in your browser February 1=2C ... | 0.126853 |
| 3753 | 3 | =?utf-8?Q?Wow...what=20an=20endorsement=21?= | View this email in your browser February 24=2C... | 0.130034 |
| 3752 | 3 | =?utf-8?Q?Residents=20Voice=20Loud=20&=20Clear... | View this email in your browser NEWS FLASH =E2... | 0.134885 |
| 1779 | 3 | =?utf-8?Q?Susan=2C=20Really=3F?= | View this email in your browser Susan Haynie's... | 0.139005 |
| 2596 | 3 | =?utf-8?Q?Here=20Are=20The=20Facts?= | View this email in your browser March 12=2C 20... | 0.139138 |
| 1942 | 4 | Technical Bulletin - System Restart TODAY... | Technical Bulletin Description: will be U... | 0.518809 |
| 684 | 4 | [cse-ms] FW: Oak Ridge Post-PhD Fellows... | FYI ________________________ David A. Bader, P... | 0.528812 |
| 4177 | 4 | [cse-phd] FW: Oak Ridge Post-PhD Fellow... | FYI ________________________ David A. Bader, P... | 0.528812 |
| 2413 | 4 | Technical Bulletin - will be UNAVAIL... | Technical Bulletin Description: will be U... | 0.546833 |
| 1824 | 4 | [Unplanned Outage] MyLLNL and Multiple LLNL Bu... | [This is a site-wide message] Description: No ... | 0.558815 |
| 2905 | 5 | [JuliaSmoothOptimizers/LinearOperators.jl] Rem... | You can view, comment on, or merge this pull r... | 0.237430 |
| 2676 | 5 | [JuliaGraphs/LightGraphs.jl] decomposition (#667) | You can view, comment on, or merge this pull r... | 0.240359 |
| 138 | 5 | [JuliaGraphs/LightGraphs.jl] rename decomposit... | You can view, comment on, or merge this pull r... | 0.255064 |
| 1603 | 5 | [JuliaGraphs/LightGraphs.jl] changes to degree... | You can view, comment on, or merge this pull r... | 0.267214 |
| 2842 | 5 | [JuliaGraphs/LightGraphs.jl] Sbromberger/more ... | You can view, comment on, or merge this pull r... | 0.275230 |
| 2149 | 6 | Rest easy. Your reservation has been confirmed... | Contact Us - Greetings James, Your reservation... | 0.321774 |
| 1880 | 6 | Rest easy. Your reservation has been confirmed... | Contact Us - Greetings James, Your reservation... | 0.321974 |
| 2299 | 6 | David Bader published new research | ResearchGate New research from your network Da... | 0.379912 |
| 1220 | 6 | James, did this researcher author this publica... | Did Rob Mccoll author this publication? Tell u... | 0.383612 |
| 3543 | 6 | Surprise Gift & Free Shipping on Dog Gifts - ... | Pre-header text goes here View online version ... | 0.403525 |
| 339 | 7 | Re: [JuliaGraphs/LightGraphs.jl] rewrite clust... | you broke it :) -- You are receiving this beca... | 0.321030 |
| 423 | 7 | Re: [JuliaGraphs/LightGraphs.jl] Replace Simpl... | @juliohm - -- You are receiving this because y... | 0.322392 |
| 2973 | 7 | Re: [weijianzhang/EvolvingGraphs.jl] use versi... | Thanks! -- You are receiving this because you ... | 0.343741 |
| 3556 | 7 | Re: [JuliaGraphs/LightGraphs.jl] WIP: Eager im... | Okay -- You are receiving this because you wer... | 0.355938 |
| 2373 | 7 | Re: [JuliaGraphs/LightGraphs.jl] Transitivity ... | Thanks! -- You are receiving this because you ... | 0.372430 |
| 588 | 8 | Re: [JuliaGraphs/LightGraphs.jl] Docs (#567) | # =3Dpr&el=3Dh1) Report > Merging src=3Dpr&el=... | 0.357735 |
| 1041 | 8 | Re: [JuliaGraphs/LightGraphs.jl] Set diagonal ... | # Report > Merging into will **not change** co... | 0.378757 |
| 143 | 8 | Re: [JuliaGraphs/LightGraphs.jl] attribution (... | # Report > Merging into will **not change** co... | 0.379303 |
| 927 | 8 | Re: [JuliaGraphs/LightGraphs.jl] attribution (... | # Report > Merging into will **not change** co... | 0.379303 |
| 1731 | 8 | Re: [JuliaGraphs/LightGraphs.jl] Update .travi... | # Report > Merging into will **not change** co... | 0.386466 |
| 42 | 9 | REMINDER: OCF Scheduled Events for Wed, | OCF Daily Reminders for Wed,::... | 0.608897 |
| 391 | 9 | REMINDER: OCF Scheduled Events for Wed, | OCF Daily Reminders for Wed, :... | 0.615778 |
| 2705 | 9 | REMINDER: OCF Scheduled Events for Thu, | OCF Daily Reminders for Thu, ::... | 0.616025 |
| 324 | 9 | REMINDER: OCF Scheduled Events for Fri, | OCF Daily Reminders for Fri, 1600-0800 ::... | 0.618132 |
| 1570 | 9 | REMINDER: OCF Scheduled Events for Wed, | OCF Daily Reminders for Wed, 0800-0900 ::... | 0.618907 |
I would put some large residual examples in this presentation, but they are mostly non-spam and have been excluded for privacy. You can run this experiment on your own emails and find that you can build a pretty good spam filter and message classifier from topic modeling with non-negative matrix factorization.
Conclusion
We can see that email inboxes (at least mine) contain several distinct topics of messages, these messages can be detected Non-negative Matrix Factorization. There is reason to believe that the residual of a topic model can be used to build a spam filter. While verification of the utility of NMF topic modeling for spam detection requires labeled data, spot checks suggest this will work.
One can learn about the structure of the topics and documents by analyzing the factors $A \approx H,W$ to gain insight into the salient features of the data detected by the algorithm.